Ambigram:Bio specializes in tailored bioinformatics consulting and data analysis services for small biotech and pharmaceutical companies, driving growth and innovation.
Our expert team offers a wide range of services, such as pipeline building, data visualization, statistical and ML-based modeling and analysis, and software and web application development focused on biological data analysis.
We understand the unique challenges faced by emerging organizations in these sectors and collaborate closely to integrate our services seamlessly into their R&D process. With our industry knowledge and cutting-edge technologies, Ambigram:Bio transforms raw data into actionable insights, enabling clients to optimize product development and deliver life-changing therapies.
Trust Ambigram:Bio to unlock your data's potential and shape the future of healthcare. Reach out to us to discuss your specific needs - our specialized team is eager to bring your vision to life!
At Ambigram:Bio, we merge data science with bioinformatics, software development, and cheminformatics. Our experience spans various biotech and pharmaceutical collaborations, either as a close partner or an independent analysis service provider.
Our projects are driven by our proprietary probabilistic data analysis platform and a wealth of curated -omics data. Learn more about these tools and how they can benefit your work by contacting us.
Pre-processing, processing, and analysis of a broad range of high-dimensional -omics data:
We have developed deep learning models and curated a compendium of drug-related data to complement our clients' projects. We are a slam-dunk choice for projects such as:
Many of our clients need to determine which targets are worth pursuing, and which ones might be poor choices. To aid your decision process, our team will help you collate multiple data resources, such as:
We model multi-omics data as a rich network replete with interactions. We carry out downstream analysis and perturbational analysis of these networks to study a variety of downstream effects:
Volumes of further expertise, examples including:
We have deep expertise technologies that have become an industry standard in computational biology. Some of the areas of our expertise and prior work include:
Please see below an overview of example webapps and visualizations that we routinely develop. These examples aren't specific to any of our clients, but rather stem from our internal experimentation and exploration of optimal ETL practices, data structures, and vizualization of various biological datatypes.
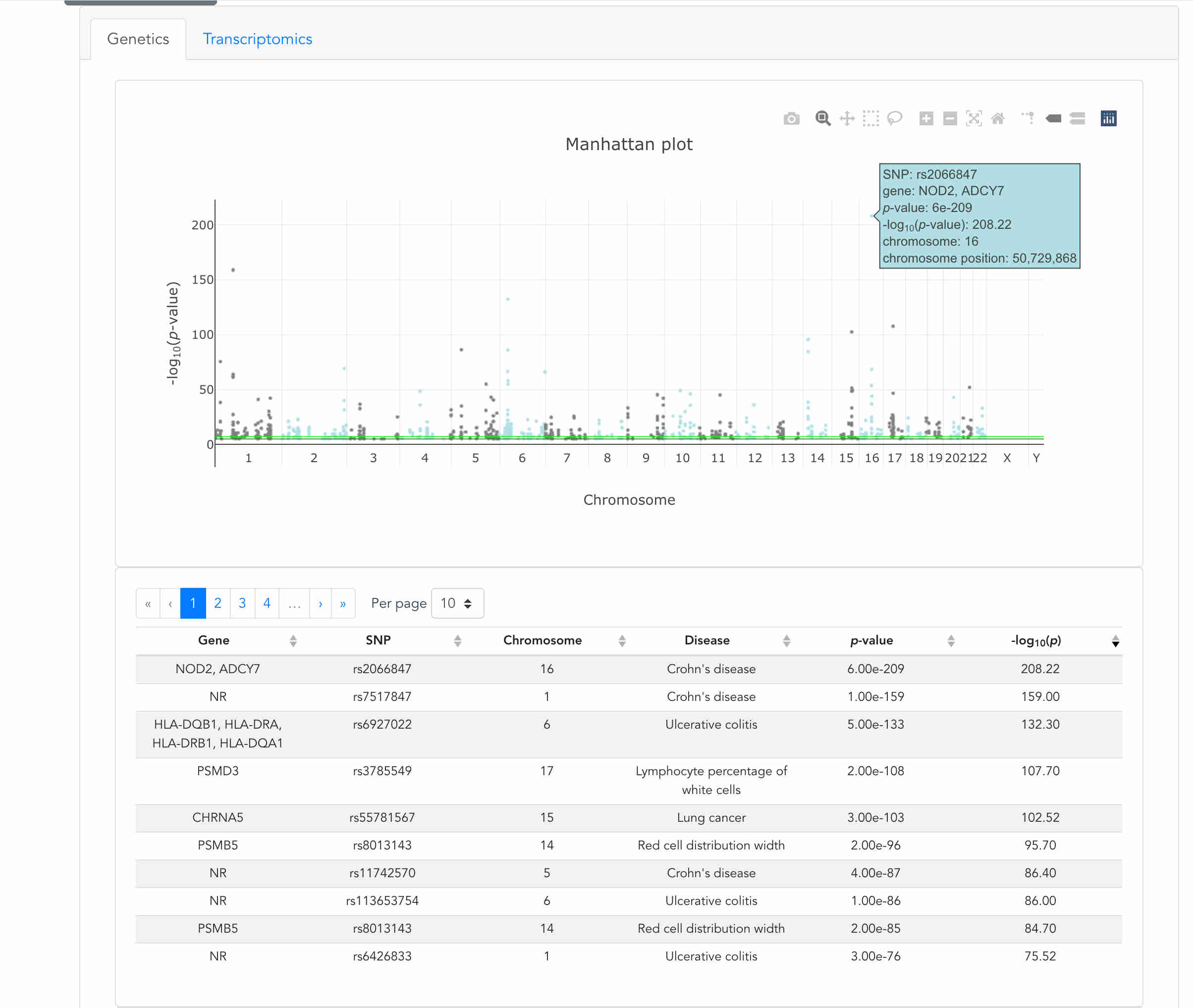
Our consultants are well versed in statistical genetics and GWAS data meta-analysis. It's only natural that our software development team has encountered this type of visualization in multiplie different projects.
The GWAS statistics in this example were gathered from public resources. This build uses Vue.js on the front end, Django on the backend, with a simple NoSQL database at the backend.
Our clients are often interested in picking the bast target. Transcriptomics is a rich resource of information on the tissue- and phenotype-dependent level of expression of each gene, with thousands of publicly available datasets.
Here we have gathered a large collection of data from GEO, and visualized it all in one spot. The data was downloaded and processed using R Bioconductor packages. The app was built using Plotly Dash.
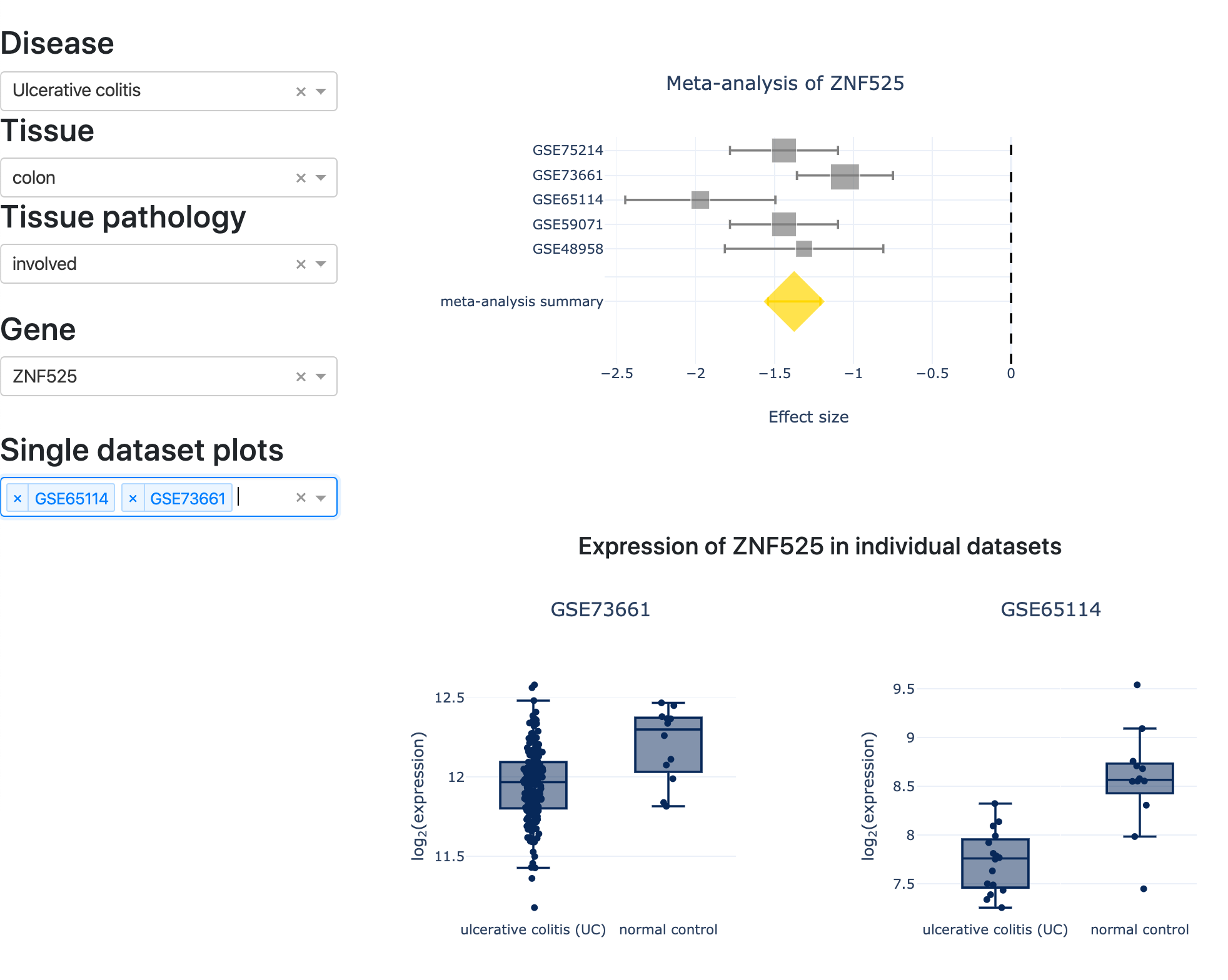
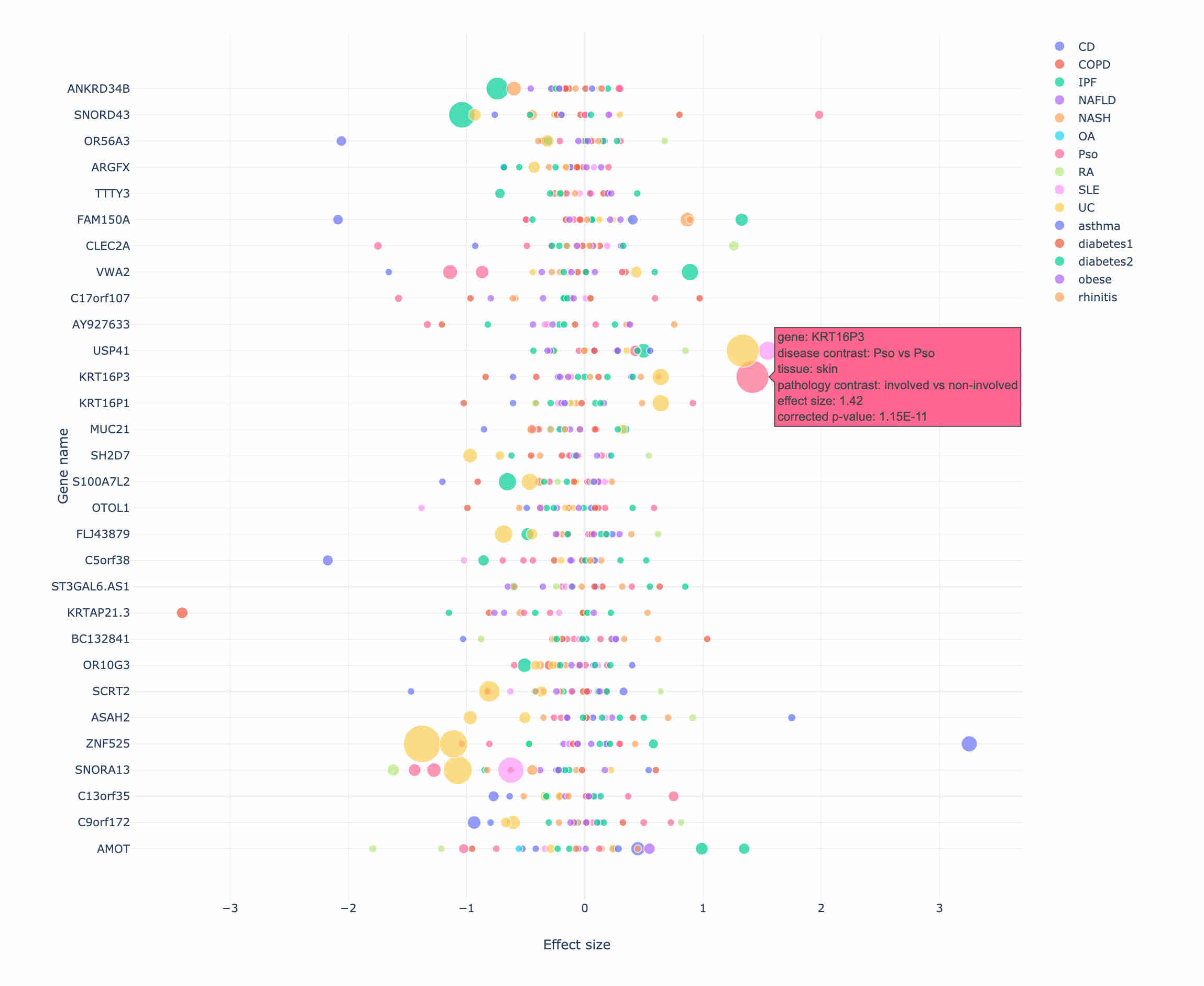
Often, a multitude of datasets is available for a given modality. In biomedical data, this is especially true for the transcriptomics data. Unfortunately, combining the findings from these datasets is non-trivial, due to batch effects, and other uncaptured covariates. In these cases, the best practice is to carry out a meta-analysis of the datasets.
In this example, we have carried out a meta-analysis of numerous datasets from GEO (fixed effects, or random effects, as appropriate) using the `metafor` library. All summary data across various diseases, tissues, and genes was stored in a Postgres database. The visualization displayed in the panel was built using R Shiny.
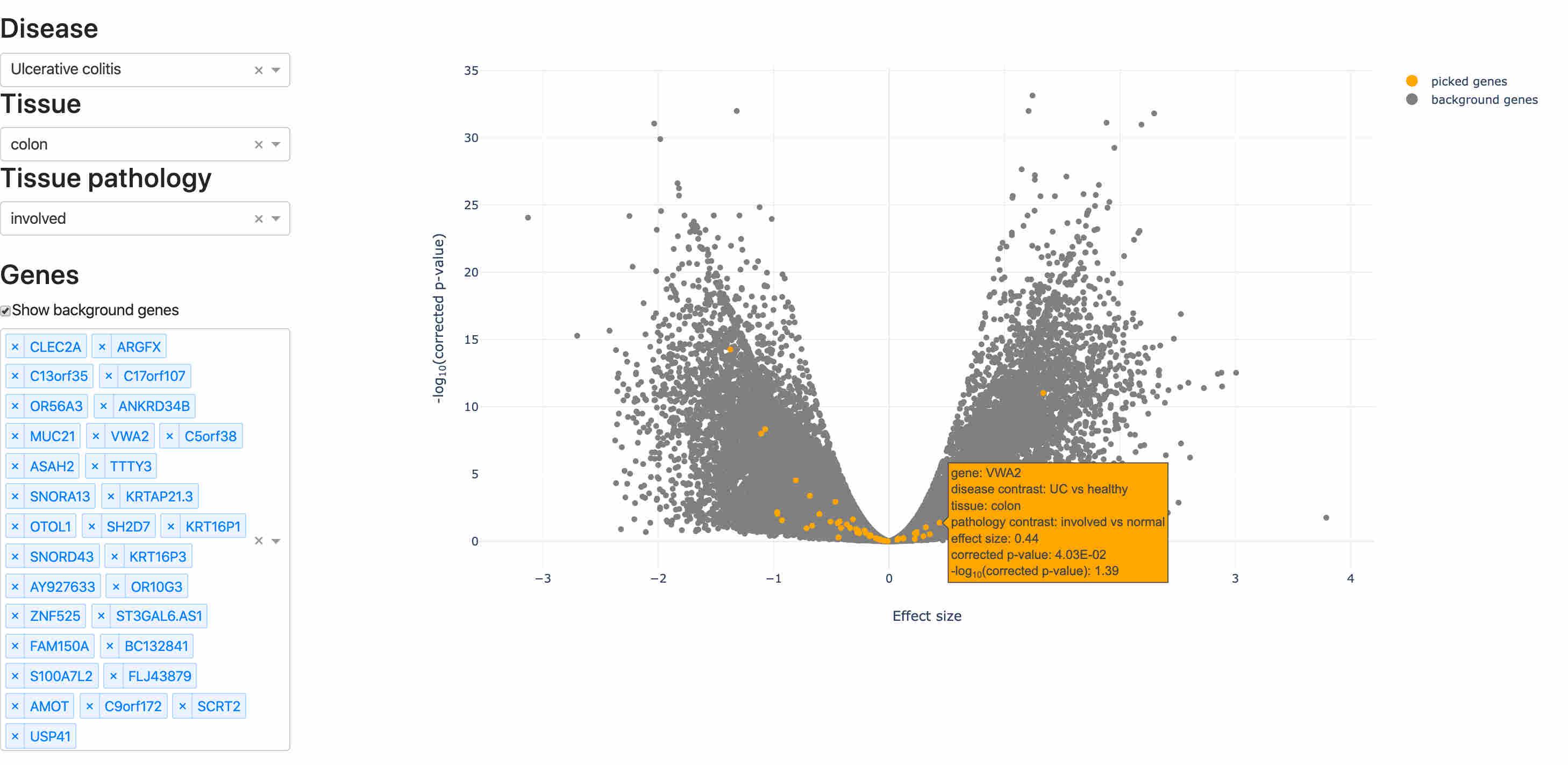
As yet another level of insight into transcriptomics data, it's quite common for our clients to be interested in a visualization of differential expression from every gene in a differential expression analysis.
Here we show an app that displays a volcano plot, and highlights a selsction of genes. Visualization coded in R Shiny, with Plotly.js powering the interactive visualization.
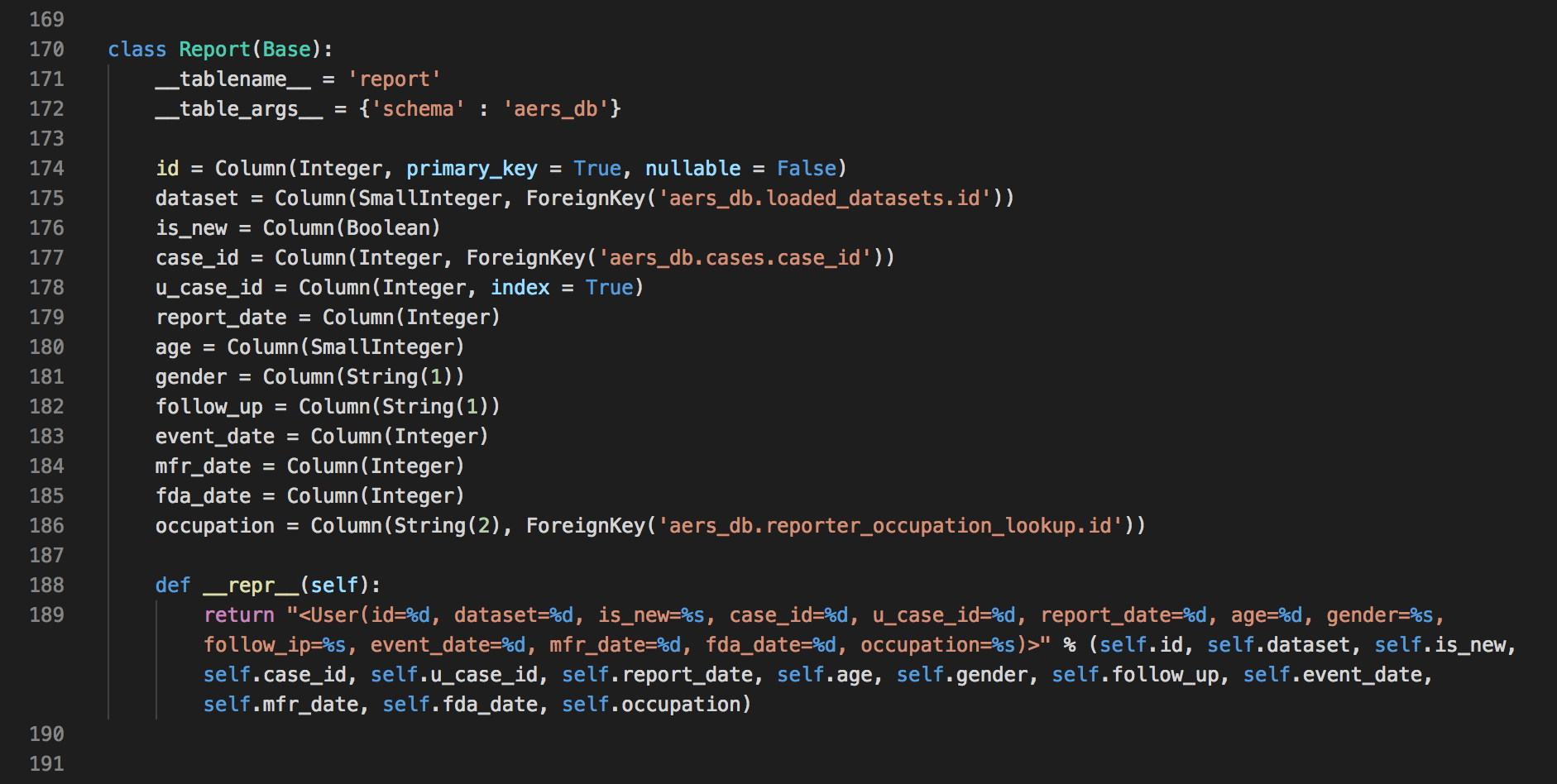
It is very common for biotech companies to generate large volumes of data. We have developed a number of solutions which helped our clents capture their data in the best format / data representation possible, store it in a queryable (if needed, relational) database, and empowered them to understand the data better by making it searchable. Client data, once it's captured properly, can be then presented to the scientists as apps (much like the ones showed above). We have also provided more powerful ways to access the data once it has been clensed - for example via universal, programmatically accessible REST APIs.
We are looking to fill positions for cross-disciplinary computational research and project data scientists and data engineers. Skill sets at the intersection of computational biology, machine learning, bioinformatics, chemoinformatics, and statistics are desired.
We are also expanding our software development team: back-end, and front-end developers, as well as devops engineers.
Reach out to us at jobs@ambigram.bio.
Poszukujemy specjalistów ds. analizy i modelowania danych (projekty w większości ukierunkowane na dane genomiczne/biologiczne). Poszukiwane są umiejętności w zakresie biologii obliczeniowej, uczenia maszynowego, bioinformatyki, chemoinformatyki, statystyki.
Rozszerzamy również nasz zespół developerów: programistów back-end, front-end oraz inżynierów devops.
Skontaktuj się z nami pod adresem jobs@ambigram.bio.
Looking for top-quality Bioinformatics consulting and software development services?
Our team of skilled professionals has the expertise and experience to provide customized solutions to meet your specific project needs. Whether you're a biotech startup or an established company, we can help you navigate the complex landscape of bioinformatics and achieve your goals. Contact us today to discuss your project needs and discover how we can help you take your research to the next level.
Don't settle for any less than Ambigram:Bio!